Entenda quem são seus clientes e como eles compram.
O retorno é rápido e certo.
Entenda quem são seus clientes e como eles compram. Atenda-os ainda melhor, maximize as vendas, evite desperdícios, otimize a logística e acompanhe todos os indicadores on-line.
Entre em contato conosco. Isto pode mudar a vida da sua empresa.
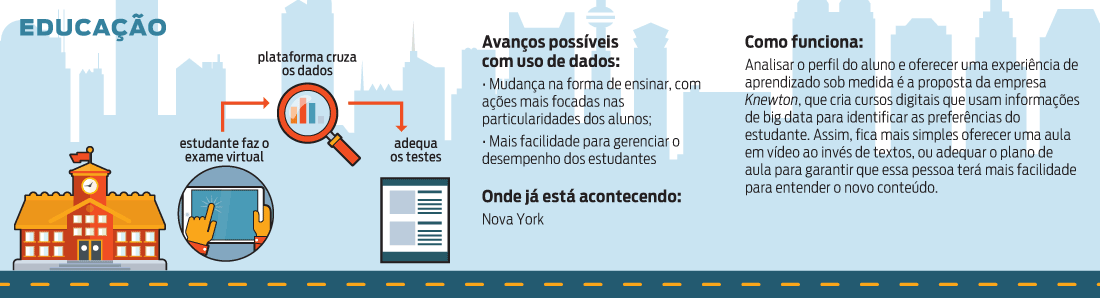
É a possibilidade de acesso a uma inimaginável quantidade de dados e informações sobre objetos, sistemas, pessoas, e a relação desses elementos entre eles mesmos. Com isso, podemos transformar tudo aquilo que conhecemos em códigos binários, permitindo medir e transformar em padrões a combinação desses códigos.
O que pode fazer?
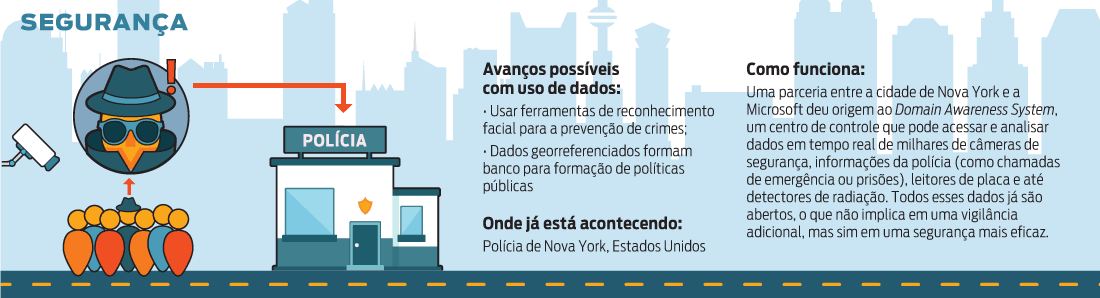
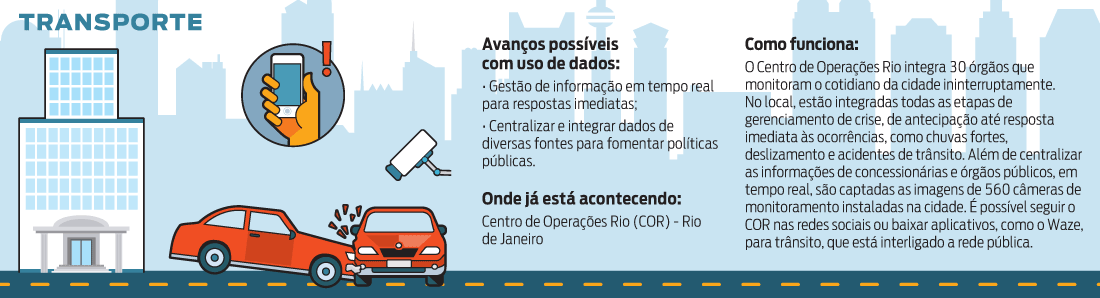
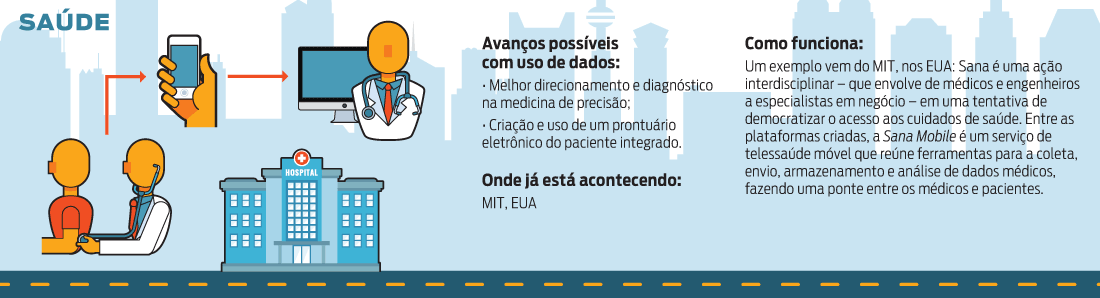
Medir e controlar quase tudo que acontece nas cidades, de sistemas de infraestrutura (como transporte, abastecimento de água, rede de esgoto, comunicação) a estratos de grupos e pessoas (perfis socioeconômicos geolocalizados podem avaliar a eficiência e necessidade de programas de saúde e educação) e monitoramento em tempo real do que ocorre nas cidades (de falhas, acidentes de trânsito a problemas de segurança).
Por que é possível?
Tudo isso já acontece em grande parte devido ao desenvolvimento de tecnologias cada vez menores, que se misturam ao ambiente na forma de sensores e microchips e podem coletar e analisar dados, promover a comunicação entre si (internet das coisas) e até disparar uma série de ações pré-programadas para reagir a determinados eventos.
Perigos
Embora prometam mais eficiência urbana, esses mecanismos também representam uma sociedade mais vigiada e controlada, com riscos como a manipulação deliberada de dados e informações, fraudes, interpretações equivocadas, uso de dados para fins obscuros, perda de privacidade e liberdades civis.
Deslize para o lado para ver o conteúdo completo
Algumas dicas para você explorar cada vez mais o mundo do BigData
O seguinte caso aconteceu com a subsidiária Toyota nos Estado Unidos:
No final da década de 1990, a Toyota U.S.A. enfrentou grandes problemas em sua cadeia de operações. O custo de armazenamento de carros se elevou e não se estava mais conseguindo fornecer o produto a tempo para os clientes. A gerência utilizava computadores que geravam uma quantidade enorme de dados e relatórios que não eram utilizados estrategicamente, que nem sempre eram exatos e que muitas vezes eram fornecidos tarde demais - o que dificultava a tomada de decisões em tempo hábil.
Barbra Cooper, CIO, identificou alguns problemas. O primeiro foi a necessidade de um Data Warehouse - um repositório central de dados, organizado e de fácil acesso. Detectou, também, a necessidade de implementação de ferramentas de software para efetuar o processamento, a exploração e a manipulação desses dados. Foi então que um sistema para fornecimento em tempo real foi implantado, mas infelizmente não funcionou de maneira correta. A entrada de dados históricos incluíam anos de erros humanos que foram despercebidos, dados duplicados, inconsistentes e falta de informações importantes. Tudo isso gerou análises, conclusões e prognósticos precipitados sobre o funcionamento da distribuidora.
Em 1999, a corporação resolveu implantar uma plataforma de Business Intelligence. Em questão de dias o sistema apresentou bons resultados. A partir dele, por exemplo, descobriram que a empresa era cobrada duas vezes por um envio especial por trem (um erro de US$ 800.000,00!).
Entre 2001 e 2005, o volume de carros negociados aumentou em 40%, o tempo de trânsito foi reduzido em 5%. Esses e vários outros benefícios ajudaram a Toyota a alcançar as maiores margens de lucro no mercado automotivo desde 2003, e vem aumentando consistentemente a cada ano. Além disso, um estudo realizado pela IDC Inc., em 2011, indicou que a instituição alcançou um retorno de pelo menos 506% sobre o investimento em BI até aquela data.
Esse é apenas um dos inúmeros casos que ilustram a ineficiência de antigos sistemas que não são capazes de suprir a enorme demanda de dados que a era da informação proporciona. O grande desafio do momento é integra-los e interpreta-los, transformando-os em informação relevante e possibilitando, assim, a devida criação de conhecimento. Através da gestão desse conhecimento nasce a inteligência!
Mais de 15 anos passaram desde o ocorrido com a Toyota, mas atualmente ainda existem muitas empresas que não utilizam corretamente os dados e informações existentes em seus bancos. E você, o que faz com os dados gerados por seus sistemas?
Você já conhece o Folding@home? Ele é um projeto de computação distribuída (distributed computing) para a simulação de enrolamentos (folding) de proteínas e das suas deformações. Através dele, a comunidade científica poderá entender melhor o desenvolvimento de diversas doenças, como Alzheimer, BSE (doença da vaca louca) e fibrose quística.
O projeto foi lançado em 1º de outubro do ano 2000 e é gerido pelo Pande Lab, grupo do departamento de Química da Universidade de Stanford, e supervisionado pelo professor Vijay S. Pande. Em 8 de março de 2004, o Genome@Home fundiu-se ao Folding@home. Atualmente é o maior projeto do gênero utilizando a plataforma BOINC (Berkeley Open Infrastructure for Network Computing).
Como funciona a computação distribuída?
O Folding@home não conta com poderosos supercomputadores para o processamento de dados. Por isso, os colaboradores principais do projeto são milhares de computadores pessoais que têm instalado um pequeno programa (client). O client é executado em background e faz uso do processador do computador enquanto ele estiver livre. Ele então conecta-se periodicamente ao servidor para transferir uma Work Unit (unidade de trabalho), pacotes de dados sobre os quais executa os cálculos. Assim que a Work Unit é completada, ela retorna ao servidor.
Os usuários ainda podem controlar suas contribuições. Até o ano de 2014, o projeto mantinha o ranking de maiores colaboradores (por usuário e por equipe) de acordo com a quantidade e a dificuldade das Work Units completadas.
O projeto já teve mais de 180.000 processadores participando ativamente do Folding@home e possui mais de 1.300.000 processadores registrados no projeto. Hoje, o Google Labs, através do Google Compute Engine, é parceiro do projeto. Com este nível de participação, o Folding@home tem um dos mais poderosos computadores no mundo, capaz de produzir cerca 175 teraflops!
“Big Data é um termo amplo para conjuntos de dados muito grandes ou complexos que aplicativos de processamento de dados tradicionais são insuficientes. Os desafios incluem análise, captura, curadoria de dados, pesquisa, compartilhamento, armazenamento, transferência, visualização e informações sobre privacidade.”
Portanto, todo o trabalho de tratamento para grandes dados que fazemos está relacionado ao projeto Folding@home. Em nossas Soluções de Apoio à Decisão, em nossos serviços de Administração de Dados e através do SetorialMetrics, utilizamos o Big Data para gerir dados complexos e realizar o processamento diferenciado de acordo com cada necessidade. Entre em contato conosco e veja no no que podemos ajudar a sua empresa.
Para quem não sabe o que é Análise Preditiva, a gente explica: é um processo que utiliza dados para descobrir padrões do passado que podem sinalizar acontecimentos futuros, auxiliando, assim, a tomada de decisões.
Hoje é o dia mundial da Saúde. Acreditamos que é uma questão de tempo até esse ramo seja revolucionado pela união de atuais e futuras inovações tecnológicas. Elas auxiliarão não apenas a tomada de decisão, como também o teste, a diagnose, a análise de comportamento, entre outras atividades importantes para o tratamento de pacientes e a gestão da saúde. Eduardo Prado, consultor de mercado em novos negócios, inovação e tendências em “Big Data” em saúde, listou 5 maneiras de alavancar a Análise Preditiva para esse propósito:
1. Estratificação de Risco Populacional
Classificar os pacientes como de baixo, médio ou alto risco. Utilizar essas informações para alocar seus recursos a nível amplo de toda a população, identificar os pacientes de alto risco, os provedores de alertas e gestores que vão cuidar desses pacientes, e definir as intervenções para impedir que outras pessoas se tornem de alto risco.
2. Automação de fluxo de trabalho
Acoplar a Análise Preditiva com as ferramentas de automação de processos que proporcionam aos provedores a capacidade de abranger os pacientes com necessidades de cuidados e permitir que os gestores atinjam aos pacientes de diversas formas, que vão desde a gerência de alto nível até a educação baseada na Web e em orientação (aconselhamento).
3.Prevenção de Reinternação
Usar a Análise Preventiva para identificar quais pacientes têm a maior probabilidade de seres reinternados. Intervir para que eles recebam o apoio que necessitem para evitar a reinternação. Aqui a estratégia para manter o paciente com a saúde estabilizada fora do ambiente hospitalar será fundamental para reduzir o risco de reinternação.
4.Atribuição de Prestador e Ajuste de Risco
Aplique o ajuste de risco para avaliar o desempenho dos prestadores de serviços individuais (por exemplo, médicos), das instalações e de toda a sua organização, em comparação com outros. Usar o ajuste de risco para medir as variações dos serviços, melhorar a qualidade e mostre aos contribuintes e prestadores como a sua organização classifica a utilização os serviços e a qualidade para a gestão da saúde.
5.Cálculos de Risco Financeiro
Calcular quanto a sua prestação de serviços provavelmente vai custar para a sua população em períodos futuros. Usar esses números para determinar se a sua organização vai perder ou ganhar dinheiro sob tipos de contratos de prestação de serviços de saúde propostos.
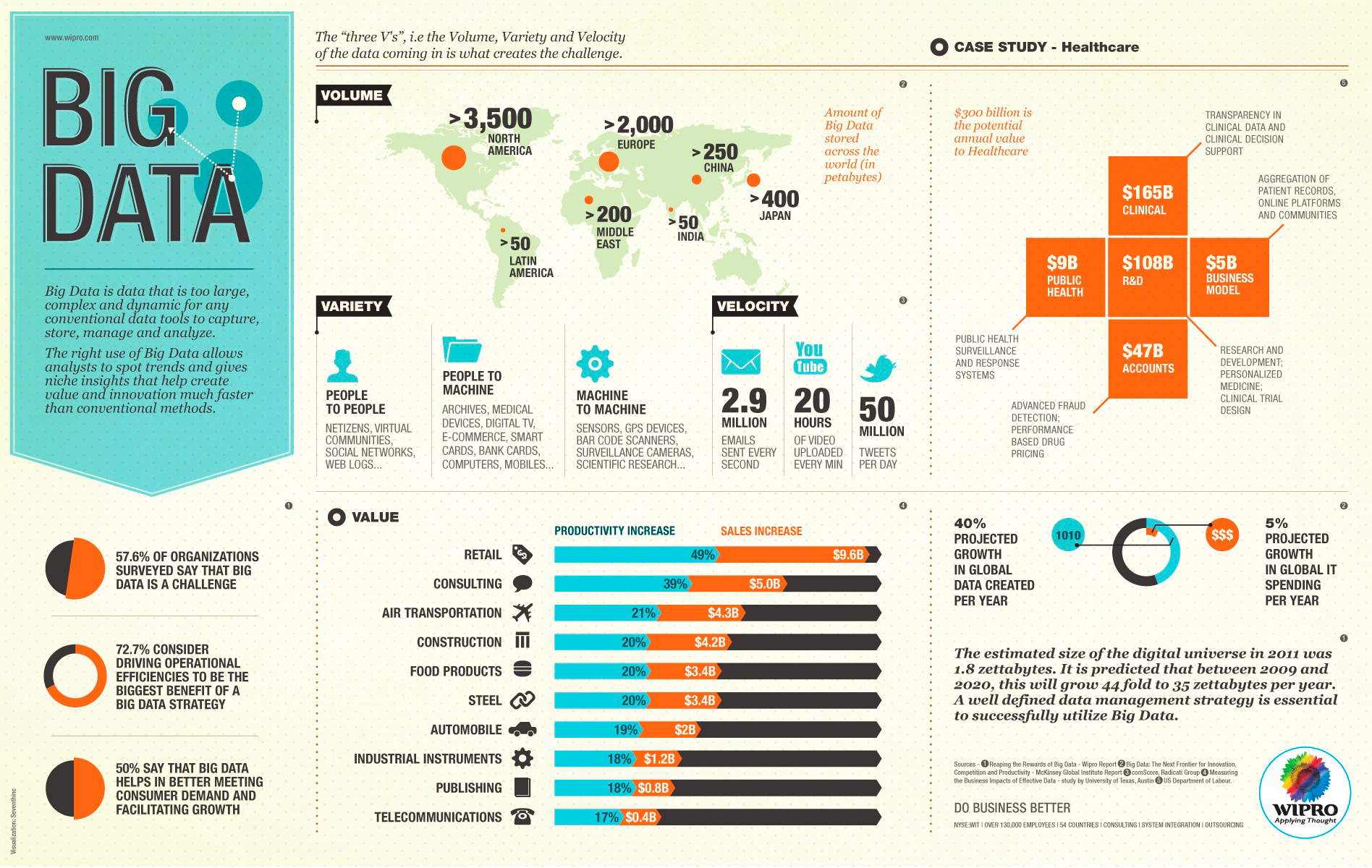
Os dados do mundo estão aumentando em níveis exponenciais. Essa enorme quantidade, pouco estruturada, advindas de fontes não tradicionais é o Big Data.
A Wikipedia define:
“Big Data é um termo amplo para conjuntos de dados muito grandes ou complexos que aplicativos de processamento de dados tradicionais são insuficientes. Os desafios incluem análise, captura, curadoria de dados, pesquisa, compartilhamento, armazenamento, transferência, visualização e informações sobre privacidade.”
O infográfico da Big Data | Visual.ly é um bom começo para quem ainda não entendeu muito bem:
(clique para ampliar)
Por que é importante?
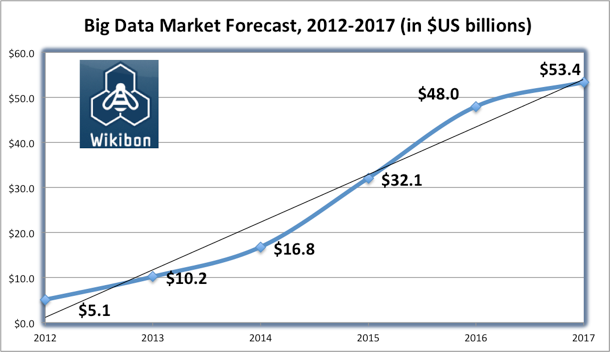
Essa explosão de dados e a análise deles tornou-se crucial para inovar e obter vantagem competitiva. Ela gera diversos insights, de formas impossíveis anteriormente. A indústria do Big Data está pronta para crescer de US$ 25 bilhões, em 2015, para mais de US$50 bilhões em 2017.
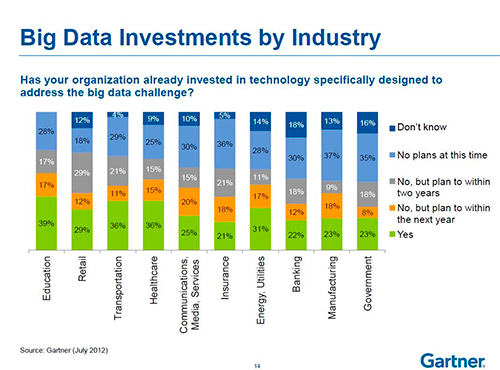
E afeta praticamente todas as outras indústrias:
O que a análise de Big Data pode fazer?
Antes as empresas se baseavam principalmente em dados transacionais armazenados de forma ordenada, porém isso mudou. Uma enorme quantidade é gerada diariamente, de diversas fontes: desde um e-mail, até um tweet. Anteriormente as organizações descartavam seus dados. Atualmente, o investimento em armazenamento e análise tornou-se acessível e obrigatório.
Por exemplo, existem 12 terabytes de tweets por dia. Depois de filtrar os ruídos, estes dados podem gerar diversos insights sobre o comportamento do consumidor.
Gráfico: comunidades diferentes interagindo.
Quais são os desafios?
- Filtrar os dados: Quais são confiáveis? Quais são atuais?
- Processamento em tempo real: Alguns dados podem perder total valos depois de algumas horas.
- Lidar com o grande volume e variedade dos dados.